Overview
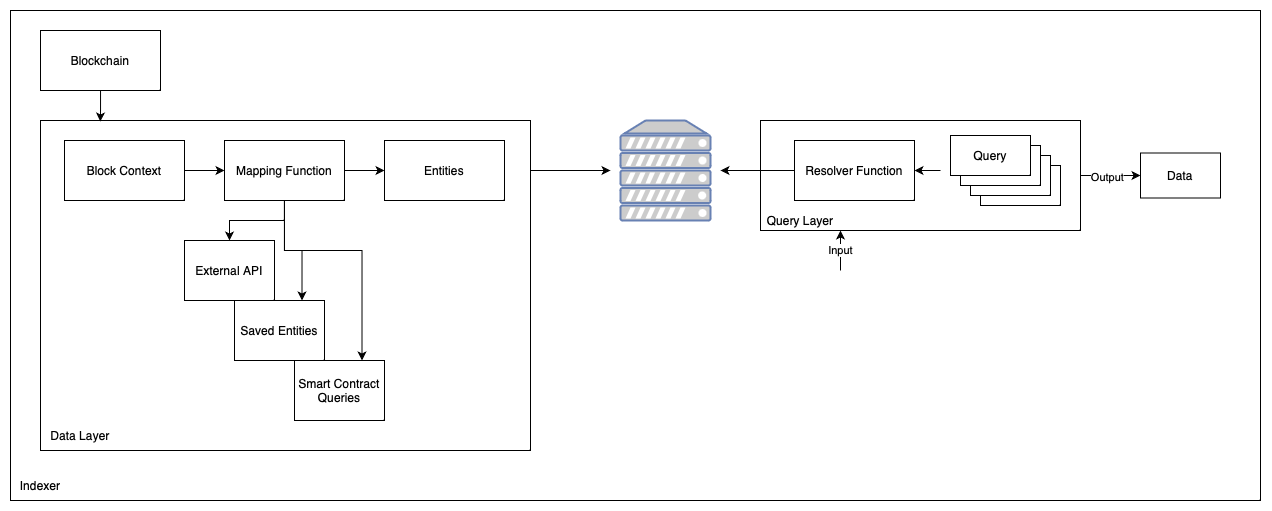
Our indexing architecture employs a two-tiered system composed of a data layer and a query layer that work in unison to populate and enable querying of a database. The data layer iterates through all blocks of a blockchain and generates entities, which are then stored in a Cassandra database. The query layer enables users to construct custom queries on top of the saved entities using a resolver function, thus facilitating retrieval of desired data.
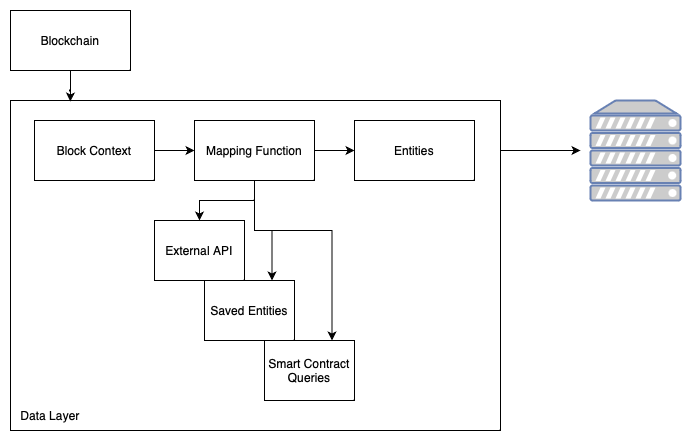
Data Layer
The data layer is a module that takes as input blocks off of a blockchain, and will produce as outputs entities that can be saved to the Cassandra database. Inside the module, we have 3 separate components.
The first component of the data layer is the Block Context, which takes input blocks from the blockchain and iterates over them to produce block contexts. These block contexts are the basis for generating entities that can represent various types of blockchain events such as swaps, transactions, sales, buys, and other relevant data.
The second component is the mapping function. In our indexing architecture, the mapping function plays a critical role in converting block contexts to entities that we can save in our Cassandra database. Using external API calls, previously saved entities, and queries to smart contracts, this function builds a new entity that consolidates all relevant information from the block context and formats it into an object we can easily query later.
In the final component of our data layer, the entities generated by the mapping function are saved to the Cassandra database for later querying.
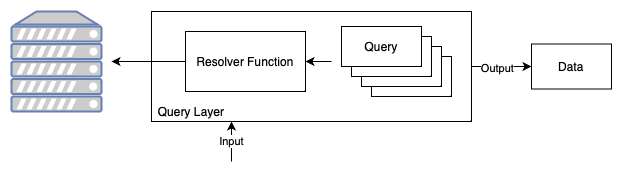
Query Layer
In our architecture, the query layer is responsible for retrieving data from our Cassandra database, which was populated by the data layer. Using custom-built queries and resolver functions, developers can access and retrieve specific data points. For instance, if we have saved relevant data about a liquidity pool in Cassandra, a developer can build queries to retrieve specific information that was saved to Cassandra, such as the average price of a swap or the total amount of fees paid for a liquidity pool.
The resolver function is used to specify the query to execute and any optional parameters, allowing for flexibility in how the function behaves. The resolver function must be called in order to fetch data, but there are no restrictions on how it operates, allowing you to tailor it to your specific needs and preferences, giving you complete control over the data retrieval process.
Indexer
In the context of blockchain, an indexer is a powerful tool that enables developers to extract valuable information from the blockchain data. With the two-layer architecture described earlier, our indexer allows you to index various blockchain entities such as liquidity pools, protocols, tokens, and more.
This provides a wealth of data for the crypto-enthusiast and developer, allowing for more sophisticated and data-driven decision-making. Whether you're looking to analyze the behavior of a specific token or to build a more efficient trading strategy, the indexer's flexibility and customizability offer endless possibilities. By leveraging the vast amount of data available on the blockchain, an indexer can enable developers to gain valuable insights and create new opportunities in the fast-moving world of cryptocurrency.
At Pulsar, we believe in empowering our customers with the tools they need to get the job done. We understand that sometimes you may not find the exact information you're looking for in the format that you need it, and that's why we encourage a "If you can't find it, build it" mentality. With our indexing architecture, you have the ability to retrieve and manipulate blockchain data in any way you see fit, allowing you to create the custom insights and reports that best fit your needs.
Data Lake
In our system, we store vast amounts of generated data in what we refer to as our "Data Lake," which is a collection of all available data, including raw and parsed blockchain data and what is accessible through both our internal and custom indexers.
This data lake offers real-time access to our indexers and, with a slight delay, to historical blockchain data. Using this data lake, you can build custom dashboards that provide valuable insights into the performance of your blockchain-based projects. In addition to having real-time access to our indexers and historical data from the blockchain, our "Data Lake" also allows you to build your own SQL queries to fetch any information you might need directly from our knowledge base.
This means you have the ability to customize your queries to fit your specific needs, and retrieve the exact data you require. With this level of flexibility and control, you can gain deeper insights into the performance of your blockchain-based projects and make data-driven decisions to optimize your strategies and achieve your goals. Whether you need to track token transfers, monitor liquidity pools, or analyze market trends, our "Data Lake" and custom SQL queries provide you with the tools you need to extract meaningful insights from the vast amount of blockchain data at your fingertips.